 Let's talk about the conveniently co-dependent relationship we've been co-evolving with Google for the past few decades, k?
Let's talk about the conveniently co-dependent relationship we've been co-evolving with Google for the past few decades, k?
Google search has trained us all into formulating questions in a sort of lazy, round-about way: "What are the best ramen restaurants in Brooklyn?"
Really though, by the time you enter that phrase, say on a cold, wintry night, Google already knows what you are going to order, or at least has the data to figure that out with a shocking certitude. Shocking! At this point, all the additional back-and-forth is just to keep the advertising industry employed.
What if, instead of search, you could request, from some agent, to deliver you the best ramen in the neighborhood and let the agent figure out the details. Using a machine learning model that included your own personal preferences and records of past behaviors, the assistant would make a selection on your behalf. And probabilistically, anyway, it would be the perfect choice.
Such a product, running on a large language model, could, some say, replace the search engine altogether. The model is the latest step in artifical intelligence. It's far from actual human intelligence, but may prove to be quite useful. Instead of just delivering a batch of results to help you make a decision, and would undertake all the steps to make that decision happen, to deliver the ramen to your door.
Until now, voice driven assistants have been pretty terse affairs. Formulate your question in a command line query (literally), and you'd receive your requested item. "Play WFMU," etc. This is about to change in a profound way.
As a content creator or sorts, I can see how interacting with these models will change the way we use language, what it will mean to "ask" about anything. It will automate much of our menial decision making, so much so that we will wonder what there is left for us to do.
Real Chat About GPT

A large language model is built on vast swaths of text data (such as the entire Internet), with the purpose of generating additional, similar text, using the statistical patterns and internal structures of the language.
The recently-launched ChatGPT is the first working prototype of what can be done with a large language model that has gained serious attention. It is a smaller variant of the much larger GPT-3 model, also developed by research company OpenAI. GPT-3 is far more powerful and has about 175 billion parameters (compared with ChatGPT's 2.6 billion parameters). The next version, is predicted to have trillions of parameters.
Despite its heft, GPT itself is not great at answering questions. To personalize answers, ChatGPT was brought in and trained to align the model to the question.
In this training phase, ChatGPT uses "reinforcement learning from human feedback" (RLHF), a set of human annotators to compare different answers to a single question, grading them in terms of how succesfully they presented the answer. These results are, in turn, fed back into the model to streamline the delivery. So, training phase, for instance, still requires human input.
Like a lazy writer, a large language model-driven engine is basically autocomplete ... on steroids. It's trained on massive amount of data, a scope that includes things like how language itself works, and on the organization of, well, all the things. From this corpus arrives the ability to predict what the next word in a sequence will be, and, likewise, what the next action will be a sequence of actions.
So in effect, it keeps predicting the next phrase to be entered in a sequence of steps, or extensions, to arrive at the final answer. It keeps going like this until, of course, it goes over a cliff, and starts just making up stuff. But you are never sure of where that edge will be, exactly.
This donut, you think to yourself, is probably not the poisoned one.
You can ask the model to translate something, or summarize something. Or just ask it a question.
I asked ChatGPT to generate a trade publication-styled article about security challenges with the Kubernetes technology. Typically, these are the kind of posts that publications or trade publications would pay writers, such as myself, a few hundred dollars each to write. They'd take a few hours to knock off. A writer could go on Google, type in "Kubernetes and Security" and start assembling an article from bits of documentation.
ChatGPT did this one in less than a minute:
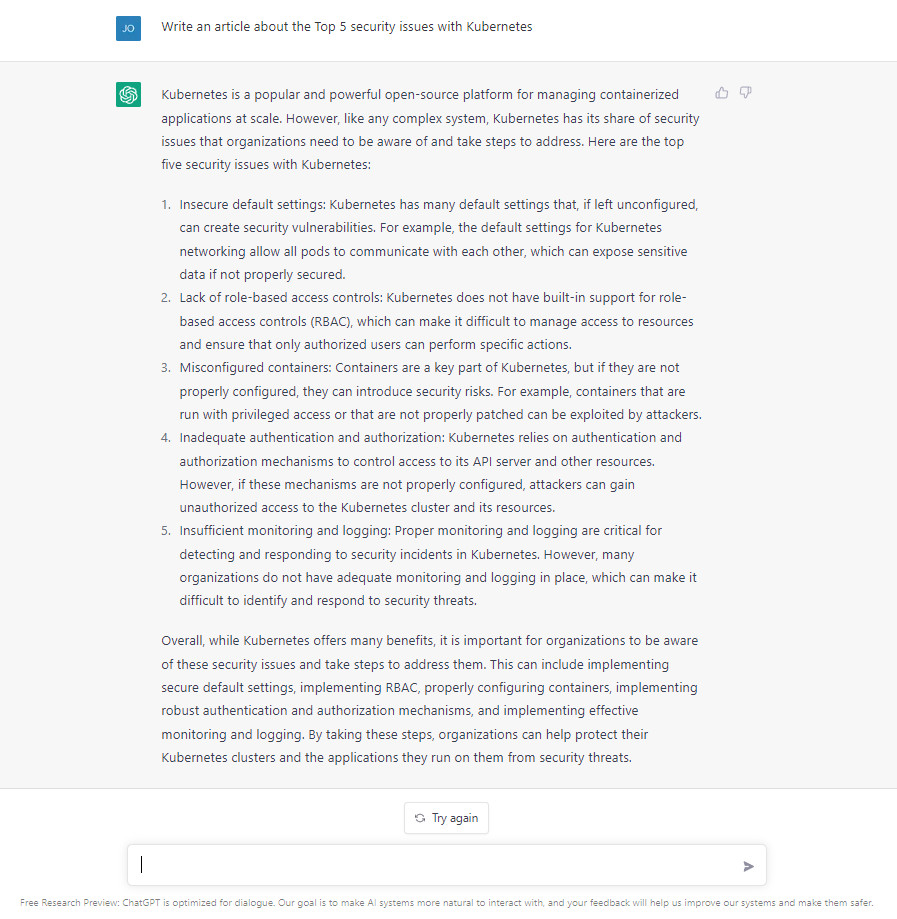
The result is surprisingly well-organized, though some of the sentences could be plagarized from source materials, and some of the material could be entirely fabricated, who knows? Article generation of this sort could create a lot of content, but at the same time, a publication would need to hire an expert to ensure all the generative material would be accurate.
Admittedly, these sorts of articles do not require a high degree of creativity -- much less than writing a play from scratch, for instance. But how many things do you do out of routine? How many actions do you take that, really, could be automated in some form? And how much of your life would you be comfortable handing off to a third party?
The more specific the question the better the response it would seem. And, most-blowingly, it can explain in whatever dialect you wish. One researcher ask ChatGPT to explain 'transfer learning' first as a rap song, then using corn analogies, then for an audience as a five year old, finally Juergen Schmidhuber talking with Hinton. ChatGPT did not miss a beat.
So what can it do? What can't it do? And what does that leave for the rest of us? These are all questions we'll be grappling with in the years to come.